16.1.1 Linear Least Squares Minimization#
The Problem#
We propose a linear functional relation between 2 measurable variables, \(x\) and \(y\):
where \(a_0\) and \(a_1\) are unknown constants. We wish to find these constants.
The Solution#
To find these unknown coefficients in practice we measure many \(x\), \(y\) pairs (assuming the measurements display some sort of dispersion). We now have a set of measured \((x_i, y_i)\) pairs for \(i = 1, 2, 3, \dots, N\).
If we assume that the \(x_i\) are free of error, we can introduce error terms \(\epsilon_i\) to the \(y_i\) data to make up for the dispersion of the data (i.e. that it doesn’t follow the linear relation exactly).
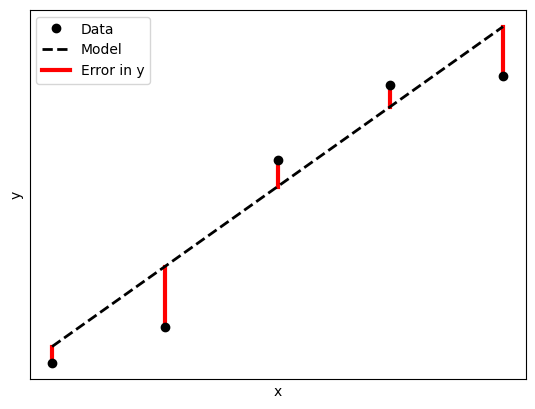
With this error term, the relation between our data points can be represented as:
\(y_i +\) \(\epsilon_i\) \(= a_0 + a_1 x_i\)
Note that, at this point the error terms we have introduced are unknown to us. They represent the difference between the measured \(y_i\) values and the expected values if we plugged \(x_i\) into our relation (for which we have yet to determine \(a_0\) and \(a_1\)). The error terms can be seen as a means to an end and will soon be done away with.
Now, we need some sort of metric to tell us how much error we have. We can use the sum of the errors squared for this:
We use the squares of the error as it is the magnitude of the errors we are concerned about, and with the errors ranging between positive and negative values, will end up canceling each other out (these are illustrated as points above and below the lines in the figure above).
We can use the relation between our data points to replace the \(\epsilon_i^2\):
Now, we want our choice of \(a_0\) and \(a_1\) to give us the least amount of error possible, or rather to give us the minimum value of \(S\). To achieve this we minimize \(S\) with respect to \(a_0\):
and \(a_1\):
To solve this system of equations we could use a matrix equation and let the computer determine the solution to that numerically, but with only two equations and unknowns, an analytic solution is easy enough to find:
and
Worked Example - Cepheid Variables
For this worked example we will use data from Cepheid variables. These are pulsating stars with their luminosity (or magnitude \(M\)) related to the period (\(P\)) of their pulsations:
Note that the relation above is can be made more accurate by including the color or temperature of the star, which we shall use later in the chapter.
As this relation is consistent across all specimens, these stars can be used as a standard candle for measuring distances, all that is needed are measurements from stars with known distances from Earth to determine \(a_0\) and \(a_1\).
The standard is to measure Cepheids in the Large Magellanic Cloud, whose distance is known.
Some such measurements can be found in the file data/cepheid_data.csv.
The data file contains measurements of:
\(\log P\)
\(M\)
\(B - V\) (color, not using yet)
We will determine \(a_0\) and \(a_1\) under 2 different assumptions:
The error in the data is associated with \(M\)
The error in the data is associated with \(\log P\) (this will require us to re-arrange things)
Solution:
You are encouraged to attempt this yourself before continuing.
We start by reading in the file. We will read the data into a 2 arrays. This can be achieved using the standard library as in the page 9.2 Structured Data Files, or using numpy.loadtxt() (documentation here). We shall use the latter as it is far more convenient:
import numpy as np
import matplotlib.pyplot as plt
logP, M, color = np.loadtxt('./data/cepheid_data.csv', delimiter = ',',
skiprows = 1, unpack = True)
The keyword arguments used above are:
delimeter: the string used to separate the data columnsskiprows: the number of rows to skip from the data file (in this case the header)unpack: this makesloadtxtreturn each column in the data file as arrays, as apposed to the default of a single 2D array.
As we will be performing 2 minimizations, we will define a function to determine \(a_0\) and \(a_1\), and \(\sigma_y\):
Show code cell content
def least_squares(x, y):
'''Least squares minimization to find the constants of a linear fit'''
mean_x = np.mean(x)
mean_y = np.mean(y)
#Note that the expectation values can be calculated using the mean function
expect_xy = np.mean(x*y)
expect_xx = np.mean(x*x)
a1 = (expect_xy - mean_x*mean_y)/(expect_xx - mean_x*mean_x)
a0 = mean_y - a1*mean_x
return a0, a1
Error in \(M\)
Let’s estimate the coefficients for the relation:
assuming the error resides primarily in \(M\).
a0, a1 = least_squares(logP, M)
Error in \(\log P\)
Now, if we assumed that the error resides primarily in \(\log P\), we want to apply least squares minimization to the relation:
to find the values for the coefficients \(b_0\) and \(b_1\). These values can be used to calculate \(a_0\) and \(a_1\) by re-arranging the relation to put \(M\) as the subject:
which gives us:
b0, b1 = least_squares(M, logP)
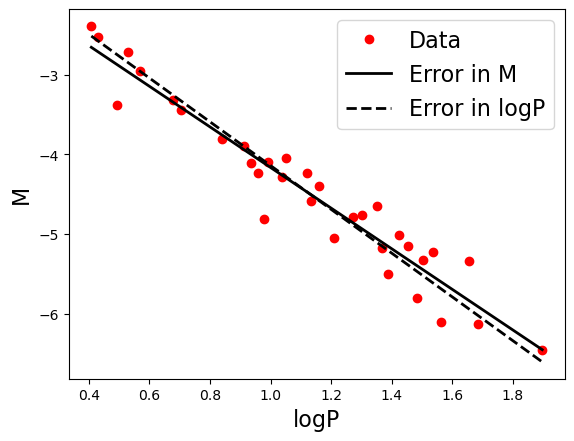
Plotting the solutions
Instead of printing out the values of the coefficients, let’s visualize them by plotting the linear relations.
Show code cell source
fontsize = 16
linewidth = 2
x = np.array([logP[0], logP[-1]]) #for the relation
y_M = a0 + a1*x #error in M
y_P = -b0/b1 + x/b1 #error in logP
fig_ceph, ax = plt.subplots()
ax.plot(logP, M, 'ro', label = 'Data')
ax.plot(x, y_M, 'k', label = 'Error in M', lw = linewidth)
ax.plot(x, y_P, 'k--', label = 'Error in logP', lw = linewidth)
ax.set_xlabel('logP', fontsize = fontsize)
ax.set_ylabel('M', fontsize = fontsize)
ax.legend(fontsize = fontsize)
plt.show()
Determining Uncertainties#
For this simple least squares minimization the only data we have is \(x_i\), \(y_i\) pairs. Although we attribute some error \(\epsilon_i\) to the \(y_i\) values (with none to \(x_i\)), we do not have a measurement for uncertainties of the \(y_i\). If we assume that the uncertainties for the \(y_i\) are uniform (\(u(y_0) = y(y_1) = \cdots = u(y_i)\)) and that the distributions of possible \(y_i\) values follows a normal distribution centered on the modelled vaule \(y(x_i)\), then the uncertinties can be approximated as:
where \(N\) is the number of data points, \(M\) is the number of constants (2 for \(a_0\) and \(a_1\)) and \(N - M\) is the number of degrees of freedom.
With uncertainties for \(y_i\), we can now determine uncertainties for the constants \(a_0\) and \(a_1\) using the combined uncertainty Equation (28) from 19.3 Combined Standard Uncertainty for uncorrelated uncertainties. Applying this to (6), we can calculate \(u(a_0)\):
Noting that \(u(y_i) = \sigma\),
and
this can be simplified to:
Similalry, from (5) we can get:
Worked Example - Cepheid Variables Model with Uncertainty
Now, let’s calculate the uncertainties for the model constants for the Cepheid variables data used above. First, we will expand on the least_squares() function defined above by including the uncertainty.
Show code cell content
def least_squares_uncertainties(x_data, y_data):
'''Least squares minimization to find the constants of a linear fit with uncertainties'''
expect_x = np.mean(x_data)
expect_y = np.mean(y_data)
expect_xy = np.mean(x_data * y_data)
expect_xx = np.mean(x_data * x_data)
#Denenator
D = (expect_xx - expect_x * expect_x)
n = y_data.size
dof = n - 2
a1 = (expect_xy - expect_x * expect_y) / D
a0 = expect_y - a1 * expect_x
u_y = np.sqrt(np.sum( (a0 + a1 * x_data - y_data)**2 ) / dof)
u_a0 = u_y * np.sqrt(expect_xx / D / n)
u_a1 = u_y / np.sqrt(D * n)
return a0, a1, u_a0, u_a1, u_y
Now to apply this to the Cepheid variables data. As before we will only use the \(\log P\) and \(M\) variables, with the model:
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
fontsize = 12
linewidth = 2
logP, M, color = np.loadtxt('./data/cepheid_data.csv', delimiter = ',',
skiprows = 1, unpack = True)
a0, a1, u_a0, u_a1, u_M = least_squares_uncertainties(logP, M)
# Plotting
logP_plot = np.array((logP.min(), logP.max()))
M_plot = a0 + a1 * logP_plot
fig, ax = plt.subplots()
ax.plot(logP, M, 'ro', label = 'Data')
ax.plot(logP_plot, M_plot, 'k', label='Model', lw=linewidth)
#Plotting expanded uncertainty
ax.plot(logP_plot, M_plot + 2 * u_M, '--k',
label='Expanded uncertainty\n(95.45% condidence)')
ax.plot(logP_plot, M_plot - 2 * u_M, '--k')
ax.set_xlabel('logP', fontsize = fontsize)
ax.set_ylabel('M', fontsize = fontsize)
ax.legend(fontsize = fontsize)
plt.show()
# Printing
print(f'u(M) = {u_M}')
print(f'a0 = {a0} ({u_a0})')
print(f'a1 = {a1} ({u_a1})')
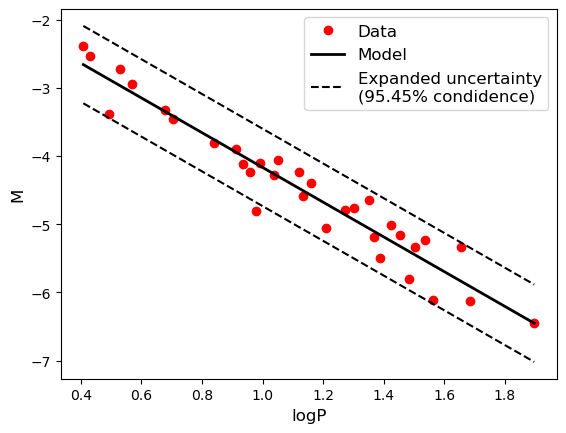
u(M) = 0.2836785277443489
a0 = -1.619033264793699 (0.15139784299976927)
a1 = -2.54732312970848 (0.12757667951220317)